

JAMstack(JavaScript,API和标记)革命正在如火如荼地进行。静态站点是安全,快速,可靠且有趣的。JAMstack的核心是静态站点生成器(SSG),它们将数据存储为平面文件:Markdown,YAML,JSON,HTML等。有时,以这种方式管理数据可能过于复杂。有时,我们仍然需要一个数据库。
考虑到这一点,Netlify(一个静态站点主机)和FaunaDB(一个无服务器的云数据库)进行了协作,使合并两个系统变得更加容易。
为什么是书签网站?
JAMstack非常适合许多专业用途,但是我最喜欢这套技术的方面之一是其进入个人工具和项目的门槛较低。
市场上有很多我可以想到的优质产品,但我没有一个完全适合您。没有人可以完全控制我的内容。没有任何东西将不付出任何代价(金钱或信息)。
考虑到这一点,我们可以使用JAMstack方法创建自己的微型服务。在这种情况下,我们将创建一个网站来存储和发布我在日常技术阅读中遇到的有趣文章。
我花了大量时间阅读在Twitter上分享的文章。当我喜欢的时候,我点击了“心脏”图标。然后,在几天之内,几乎不可能找到大量新的收藏夹。我想构建一些与“内心”相似的东西,但我拥有并控制。
我们该怎么做?我很高兴你问。
有兴趣获取代码吗?您可以在Github上获取它,也可以直接从该存储库直接部署到Netlify!在这里看看成品。
我们的技术
托管和无服务器功能:NETLIFY
对于托管和无服务器功能,我们将利用Netlify。另外,通过上述新协作,Netlify的CLI(“ Netlify Dev”)将自动连接到FaunaDB,并将我们的API密钥存储为环境变量。
数据库:FAUNADB
FaunaDB是一个“无服务器” NoSQL数据库。我们将使用它来存储书签数据。
静态网站生成器:11TY
我是HTML的忠实拥护者。因此,本教程将不会使用前端JavaScript来呈现我们的书签。相反,我们将利用11ty作为静态站点生成器。11ty具有内置的数据功能,使从API提取数据就像编写几个简短的JavaScript函数一样容易。
IOS捷径
我们需要一种简单的方法将数据发布到我们的数据库中。在这种情况下,我们将使用iOS的“快捷方式”应用程序。也可以将其转换为Android或桌面JavaScript小书签。

通过Netlify Dev设置FaunaDB
无论您已经注册FaunaDB还是需要创建一个新帐户,在FaunaDB和Netlify之间建立链接的最简单方法是通过Netlify的CLI:Netlify Dev。您可以在此处找到FaunaDB的完整说明,也可以按照以下说明进行操作。
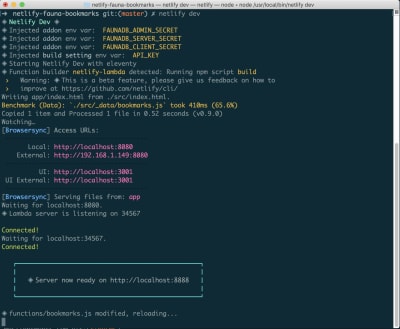
如果尚未安装此程序,则可以在终端中运行以下命令:
在您的项目目录中,运行以下命令:
一旦全部连接,就可以netlify dev在项目中运行。这将运行我们设置的所有构建脚本,而且还将连接到Netlify和FaunaDB服务并获取任何必要的环境变量。便利!
创建我们的第一个数据
从这里,我们将登录FaunaDB并创建我们的第一个数据集。我们将从创建一个名为“书签”的新数据库开始。在数据库内部,我们有馆藏,文档和索引。
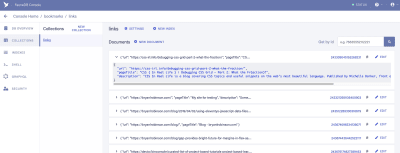
集合是数据的分类组。每条数据都采用文档的形式。根据Fauna的文档,文档是“ FaunaDB数据库中的单个可更改记录”。您可以将Collections视为传统的数据库表,将Document视为一行。
对于我们的应用程序,我们需要一个Collection,我们将其称为“链接”。“链接”集合中的每个文档都是具有三个属性的简单JSON对象。首先,我们将添加一个新文档,该文档将用于构建第一个数据获取。
这为我们需要从书签中提取信息的基础,并为我们提供了第一组数据以提取到模板中。
如果您像我一样,就想马上看到您的工作成果。让我们在页面上获取一些东西!
安装11ty并将数据拉入模板
由于我们希望书签以HTML呈现,而不是由浏览器获取,因此我们需要做一些事情来呈现。有很多很棒的方法,但是为了方便和省电,我喜欢使用11ty静态站点生成器。
由于11ty是JavaScript静态网站生成器,因此我们可以通过NPM安装它。
通过该安装,我们可以运行eleventy或eleventy --serve在我们的项目中启动并运行。
Netlify Dev通常会检测到11ty为要求并为我们运行命令。要进行这项工作-并确保我们已准备好进行部署,我们还可以在中创建“ serve”和“ build”命令package.json。
11TY的数据文件
大多数静态站点生成器都有内置的“数据文件”的概念。通常,这些文件将是JSON或YAML文件,允许您向网站添加其他信息。
在11ty中,您可以使用JSON数据文件或JavaScript数据文件。通过利用JavaScript文件,我们实际上可以进行API调用,并将数据直接返回到模板中。
默认情况下,11ty希望将数据文件存储在_data目录中。然后,您可以通过在模板中使用文件名作为变量来访问数据。在本例中,我们将在处创建一个文件,_data/bookmarks.js并通过{{ bookmarks }}变量名对其进行访问。
如果您想更深入地了解数据文件配置,则可以通读11ty文档中的示例,或者查阅有关如何将11ty数据文件与Meetup API一起使用的教程。
该文件将是一个JavaScript模块。因此,为了使一切正常工作,我们需要导出数据或函数。在我们的例子中,我们将导出一个函数。
让我们分解一下。在这里,我们有两个功能在做主要工作:mapBookmarks()和getBookmarks()。
该getBookmarks()函数将从FaunaDB数据库中获取我们的数据,mapBookmarks()并将获取一组书签并对其进行重组,以使其更适合我们的模板。
让我们更深入地研究getBookmarks()。
getBookmarks()
首先,我们需要安装并初始化FaunaDB JavaScript驱动程序的实例。
现在我们已经安装了它,让我们将其添加到数据文件的顶部。该代码直接来自Fauna的docs。
之后,我们可以创建函数。我们将从使用驱动程序上的内置方法构建第一个查询开始。代码的第一部分将返回数据库引用,我们可以使用该数据库引用来获取所有带有书签的链接的完整数据。我们使用此Paginate方法,如果决定在将数据交给11ty之前先对数据进行分页,则可以作为管理光标状态的助手。在本例中,我们将只返回所有引用。
在此示例中,我假设您通过Netlify Dev CLI安装并连接了FaunaDB。使用此过程,您可以获得FaunaDB机密的本地环境变量。如果您未以这种方式安装它或未netlify dev在项目中运行,则需要一个类似dotenv创建环境变量的包。您还需要将环境变量添加到Netlify站点配置中,以便稍后进行部署。
此代码将以参考形式返回我们所有链接的数组。现在,我们可以构建一个查询列表以发送到我们的数据库。
从这里,我们只需要清理返回的数据。那就是mapBookmarks()进来的地方!
mapBookmarks()
在此功能中,我们处理数据的两个方面。
首先,我们在FaunaDB中获得了一个免费的dateTime。对于创建的任何数据,都有一个timestamp(ts)属性。它的格式化方式不令Liquid的默认日期过滤器满意,因此让我们对其进行修复。
这样,我们就可以为数据构建一个新对象。在这种情况下,它将具有一个time属性,并且我们将使用Spread运算符对我们的data对象进行解构以使它们全部处于一个级别。
这是我们执行功能之前的数据:
这是我们的功能之后的数据:
现在,我们已经有了格式正确的数据,可以为我们的模板做好准备!
让我们编写一个简单的模板。我们将遍历书签并验证每个书签都有一个pageTitle和一个,url因此我们看起来并不傻。
现在,我们正在提取和显示FaunaDB中的数据。让我们花点时间考虑一下,它呈现出纯HTML有多么好,并且不需要在客户端获取数据!
但这还不足以使它成为对我们有用的应用程序。让我们找出比在FaunaDB控制台中添加书签更好的方法。
输入Netlify函数
Netlify的Functions附加组件是部署AWS lambda函数的更简单方法之一。由于没有配置步骤,因此非常适合只想编写代码的DIY项目。
该函数将位于您项目中的URL上,如下所示:https://myproject.com/.netlify/functions/bookmarks假设我们在函数文件夹中创建的文件为bookmarks.js。
基本流程
- 将网址作为查询参数传递给我们的函数网址。
- 使用该功能加载URL并刮取页面的标题和描述(如果有)。
- 格式化FaunaDB的详细信息。
- 将详细信息推送到我们的FaunaDB Collection。
- 重建站点。
要求
构建这些组件时,我们需要一些软件包。我们将使用netlify-lambda CLI在本地构建函数。request-promise是我们用于发出请求的软件包。Cheerio.js是一个包,我们将使用它从请求的页面中抓取特定项目(以jQuery为Node)。最后,我们需要FaunaDb(应该已经安装了。)
安装完成后,让我们配置项目以在本地构建和提供功能。
我们将修改我们的“ build”和“ serve”脚本,package.json使其看起来像这样:
警告: 使用Webpack进行编译时,Fauna的NodeJS驱动程序存在错误,Netlify的Function用于构建该错误。为了解决这个问题,我们需要为Webpack定义一个配置文件。您可以将下面的代码保存到一个新的 – 或现有的 – webpack.config.js。
一旦该文件存在,当我们使用netlify-lambda命令时,我们需要告诉它从此配置运行。这就是为什么我们的“服务”和“构建脚本”使用该--config命令的值的原因。
功能客房整理
为了保持主函数文件尽可能整洁,我们将在单独的bookmarks目录中创建函数,并将其导入到主函数文件中。
getDetails(url)
该getDetails()函数将采用从我们的导出处理程序传入的URL。从那里,我们将通过该URL到达该站点,并获取页面的相关部分以将其存储为书签的数据。
我们首先需要我们需要的NPM软件包:
然后,我们将使用该request-promise模块为请求的页面返回HTML字符串,并将其传递cheerio给我们,以提供一个非常类似于jQuery的界面。
从这里,我们需要获取页面标题和元描述。为此,我们将像在jQuery中一样使用选择器。
注意: 在此代码中,我们 'head > title' 用作选择器来获取页面标题。如果不指定此选项,则最终可能会 在页面上的所有SVG内获取<title> 标签,这不理想。
有了数据,现在该将书签发送到FaunaDB中的收藏了!
saveBookmark(details)
对于我们的保存功能,我们希望将获取自的详细信息getDetails以及URL作为单个对象传递。Spread运算符再次发出警告!
在我们的create.js文件中,我们还需要要求并设置我们的FaunaDB驱动程序。从我们的11ty数据文件中应该看起来非常熟悉。
一旦解决了这些问题,就可以编写代码。
首先,我们需要将详细信息格式化为Fauna期望查询的数据结构。Fauna期望对象的数据属性包含我们要存储的数据。
然后,我们将打开一个新查询以添加到我们的收藏夹中。在这种情况下,我们将使用查询帮助器并使用Create方法。Create()有两个参数。首先是要在其中存储数据的Collection,第二个是数据本身。
保存后,将成功或失败返回给处理程序。
让我们看一下完整的Function文件。
rebuildSite()
独具慧眼的人会注意到,我们在处理程序中又引入了一个函数:rebuildSite()。每当我们提交成功的新书签保存时,此功能将使用Netlify的Deploy Hook功能从新数据重建站点。
在Netlify中站点的设置中,您可以访问Build&Deploy设置并创建一个新的“ Build Hook”。挂钩具有一个名称,该名称显示在“部署”部分中,并且可以根据需要选择一个非主分支进行部署的选项。在本例中,我们将其命名为“ new_link”并部署我们的master分支。
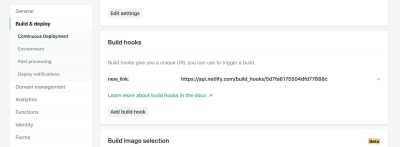
从那里,我们只需要向提供的URL发送POST请求。
我们需要一种发出请求的方式,并且由于已经安装了request-promise,因此我们将继续在该文件的顶部要求使用该软件包。
设置IOS快捷方式
因此,我们有一个数据库,一种显示数据的方法和一种添加数据的功能,但是我们仍然不是很友好。
Netlify为我们的Lambda函数提供了URL,但是在移动设备中键入它们并不有趣。我们还必须将URL作为查询参数传递给它。那是很多努力。我们如何才能尽力而为呢?

Apple的“快捷方式”应用程序允许构建自定义项目进入您的共享表。在这些快捷方式中,我们可以发送在共享过程中收集的各种类型的数据请求。
这是逐步的快捷方式:
- 接受任何项目并将该项目存储在“文本”块中。
- 将该文本传递到“脚本”块中以进行URL编码(以防万一)。
- 使用我们的Netlify函数的URL和一个查询参数将该字符串传递到URL块中
url。 - 在“网络”中,使用“获取内容”块以POST到JSON的形式发送到我们的URL。
- 可选:从“脚本”“显示”最后一步的内容(以确认我们要发送的数据)。
要从共享菜单访问此文件,我们打开此快捷方式的设置,然后打开“在共享表中显示”选项。
从iOS13开始,可以共享这些“操作”并将其移到对话框中的较高位置。
现在,我们有了一个可以在多个平台上共享书签的“应用程序”!

